Beyond AI proof of concepts: How the tech challenges change as your adoption of AI grows
In 2024, we've increasingly seen clients move beyond AI proof of concepts & pilots. They’re getting their 1st production successes, which opens the door to real business impact and a portfolio of AI use cases. Along this journey — from PoC to production & portfolio — we've seen how the technical challenges can change drastically. And knowing what is needed at each stage is crucial to success.

From proof of concept to production
When building a custom AI use case, the starting point is usually a PoC to define what really works. This gives you a tangible prototype that raises the level of discussion and helps to inform smart investment decisions. Typically, you need at least four weeks and up to twelve weeks for the most complex use cases. The goal is to learn as fast as possible: is the use case technically feasible? How should it be implemented to fit your existing tech landscape? Will it provide the user/business value needed to create a strong business case?
When you go into production, the game changes. To capture the potential value you’ve identified, you need to create the UX and accuracy for high adoption. You also need to consider how to build a cost-efficient, scalable, and maintainable solution that can keep providing value over time.
We see many clients getting stuck in PoC mode — so much so that the term is almost forbidden in some places. They build a bunch of ‘cool & interesting’ Streamlit demos and generate endless slides explaining how AI is changing ~everything. But they don’t break through with any real business impact. Of course, that’s the result of many things beyond technology, from use case selection to process development, change management, and beyond. But one overlooked challenge is adapting your development approach from PoCs to production implementations.
Here are some key shifts we’re typically making:
| Proof-of-Concept | Production | |
|---|---|---|
| AI Models & techniques | Always start with the leading proprietary LLMs (currently GPT 4o, o1, Claude Sonnet 3.5, etc). They’re the most capable models & offer easy tools for secure development (like Azure OpenAI Service). So, they provide the quickest path to validating the feasibility and potential impact of an AI use case. Prototype with prompt engineering first - as it enables you to progress quickly. Then set up evaluation, so you can systematically test what works. Often that means exploring RAG and/or agentic approaches, but rarely fine-tuning. | Leading LLMs are also slow, hard to scale & expensive, so we often look to limit their usage wherever possible in production. This can mean using traditional ML tools, smaller models (like Phi-3 or open-source models like Llama 3), or fine-tuning cheaper models to specialize on a particular task. In almost all of our production use cases, we’re using leading LLMs as just one part of the broader data & AI toolbox. |
| UX | Build prototypes and PoCs in a simple standalone UI (with UI libraries like Streamlit / Gradio / Dash). You need a plan for a production UX that will drive adoption. But you shouldn’t invest time in frontend development & integration, before validating what works and will provide real value. | People don’t want yet another UI to interact with, so we typically aim to integrate validated solutions into the tools that already have people’s attention. For example, we’ve created Teams Apps, Slack Apps, Salesforce flows and integrated solutions into custom CPQs, company websites & intranets. Whatever it is, the UX becomes crucial. However nice your business case looks, it will mean nothing if people don’t actually use what you build! |
| Infra, data & governance |
|
|
| Team | Small, cross-functional team with the mandate to move fast & break things. Typically we aim for a team with a combination of data science, design & business expertise. They need to be supported by a business owner with the drive (and budget) to make things happen. And frontline representation to keep them close to the real problems. | Once we’ve validated what works and are looking to scale, we need to involve a wider group of stakeholders and change agents to create a safe, integrated & reliable solution, then drive real adoption & behavior change. This usually means HR, legal, IT and frontline change agents with the social capital to drive adoption. |
Overall, this message is far from groundbreaking. At the PoC phase, you need to organize for fast learning. When going to production, you need to organize to deliver fast business value. Might be obvious, but we see many failing to implement this message in practice!
Scaling from your first production case to an AI portfolio
When you have a successful AI solution in real use, the awareness, momentum and demand for more will usually grow. Managing the resulting shift from one use case to many creates a whole set of new technical challenges. You will learn a lot from your first use case, and you’ll create data assets and AI capabilities that can be reused in other areas. So if you rush into the next use cases without building on this learning, you’ll waste a significant amount of time and money reinventing the wheel. And you’ll probably create a mess. To avoid this, you need to start building common development enablers between use cases to guide people on everything from cloud infrastructure choices to RAG optimization techniques, evaluation frameworks, and much more.
This is typically led by IT in collaboration with the business units driving your first AI use cases. It requires a careful balancing act between capturing the efficiencies of global consolidation while enabling local flexibility where it matters most. Different models and infrastructure providers have different strengths. The same goes for all sorts of supporting libraries and ML tools that might be needed. And these differences can be crucial in making use cases viable or not. So, you need to be careful about where to restrict people’s choices.
To get you thinking, here’s one approach to strike the right balance:
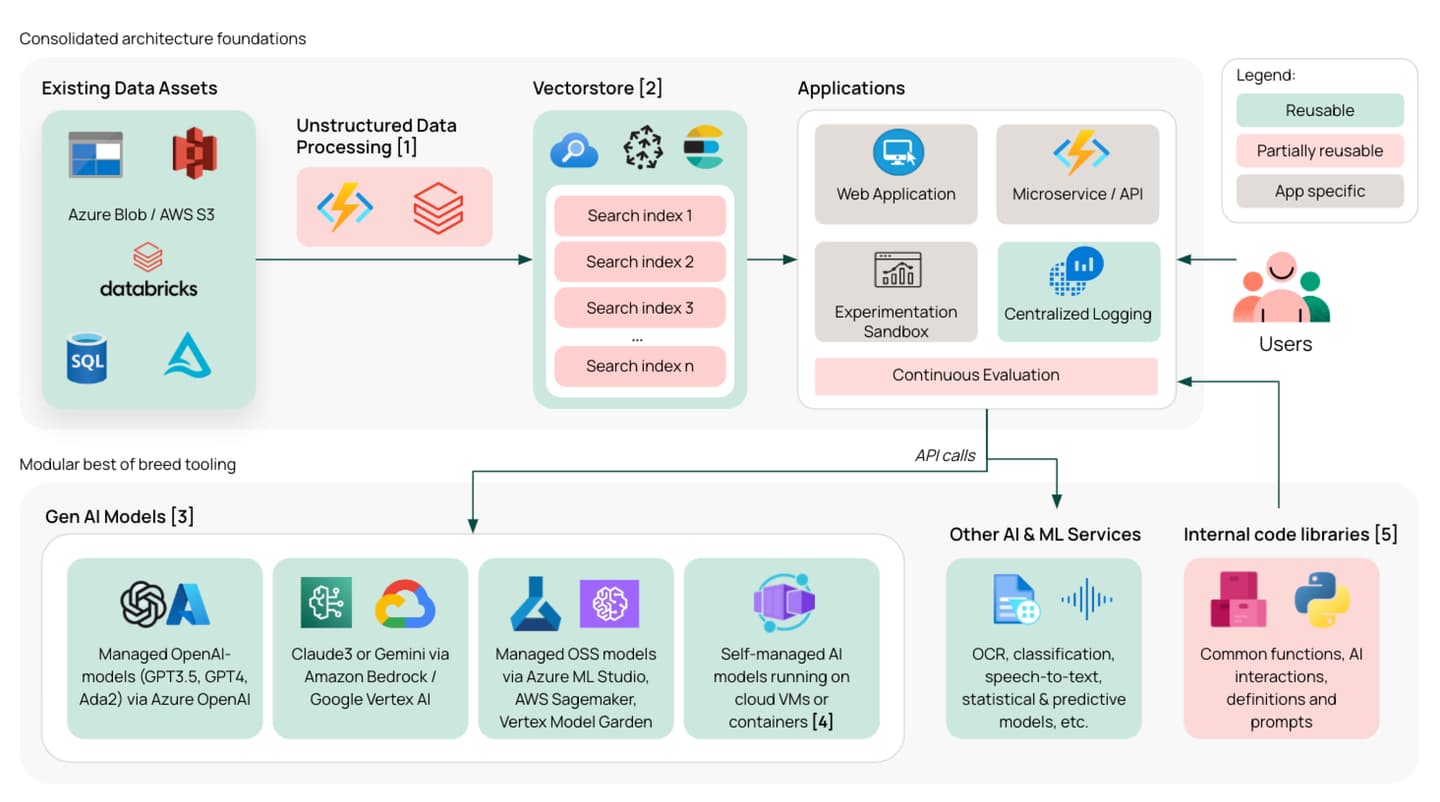
Some notes:
- Processing existing data assets for AI applications typically includes steps such as OCR, text-chunking, vector-encoding, entity extraction, summarization, and enriching with additional metadata. Here, we can also have different pre-processing configurations to serve the needs of different applications.
- Within the Vectorstore (like Azure AI Search, Pinecone, or Elasticsearch), we can create separate indexes/collections based on user groups. Where there is overlap in the data used by our different applications (as there often is), we can design indexes to be reusable to reduce duplication.
- The various AI-model services are basically just endpoints that can be called through the web, returning a response from the model. Their APIs are also nearly identical, following a standard set by OpenAI, so swapping a model typically involves minimal code changes. This makes the models easily interchangeable by design, including across platforms (Azure, AWS, GCP). Today, we almost always start with OpenAI’s models, then consider a wider range of options when we’re optimizing in production.
- Running self-managed compute allows you to run open-source and fine-tuned models while avoiding some of the limitations of managed services - namely insufficient rate limits and lack of SLAs. With high-usage production cases, this can be more cost-efficient than the token-based pricing of managed services.
- Alongside the cloud resources, we should also create reusable assets for writing the applications’ code. With an internal code package, we can ensure the reuse of commonly used functions, infrastructure as code, AI interactions, definitions, and prompts. This can include a ‘reference implementation’ that offers those developing use cases a deployable skeleton application to use as a starting point for any development. With this, people can get moving as fast as possible without the initial learning and tool selection stage getting in their way. Publishing such packages is relatively straightforward, for example, using Azure Artifacts.

Overall, there are a few key goals here:
- Consolidate the data and application infrastructure to minimize the need for extra configurations, pipelines, and skill sets.
- Give freedom to adopt the best AI models and ML services, as these can have a big impact on the quality of your final application.
- Create reusable assets wherever possible to make it as easy, efficient, and safe as possible for new use cases to get started. Of course, in addition to architecture, this involves ways of working, such as defining preferred programming languages and frameworks (LangChain, LlamaIndex, or no-frameworks), or adopting an ‘API-first' development philosophy.
Overall, the correct approach will depend heavily on your existing infrastructure, capabilities, and use cases. But hopefully, this gives you some ideas for how to reuse the technical knowledge and assets created between use cases, so you can achieve high-velocity development at scale.
Challenges beyond technology
As always, technology is only one part of the story. Getting to production and developing a portfolio of successful AI use cases requires a whole lot more, from identifying the right use cases in the first place to navigating organizational budgets, to defining your broader AI strategy and operating model.
You can read more about those in our Gen AI working paper. This blog post is the third in a series that revisits its best learnings, with a few updates thrown in. You can go back to the first one here. Please get in touch if you want to discuss this further!
 Jack RichardsonHead of Data & AI Transformation
Jack RichardsonHead of Data & AI Transformation





